SYCL: A Portable Alternative to CUDA
As you probably know, many of AI frameworks depend on CUDA to make AI work on GPUs. CUDA is a language extension to C that only works for Nvidia GPUs. The industry recognizes this dependency and there is quite some work being done to create a portable alternative to CUDA. ZLUDA recently made news as a portable version of CUDA but it is not funded anymore. UXL Foundation was formed by a consortium led by Google, Intel, Qualcomm and ARM to solve this issue. Key component from UXL foundation is a standard for CUDA alternative from Khronos group called SYCL.
SYCL
Khronos group is a non profit industry consortium that creates interoperability standards. Its major accomplishments include OpenGL and Vulkan for gaming/graphics. Nowadays, every major game engine implements one of these two standards. OpenCL was their attempt to create a similar standard for computation. Its history is nearly as old as CUDA’s. Unfortunately, it has not become a driving force in the computing industry like OpenGL/Vulkan in gaming. This is mainly because OpenCL is very low level, lacking many useful abstractions.
SYCL is a sort of successor to OpenCL with useful abstractions and is designed to be implemented for all GPUs. It is a reference standard rather than an implementation. In other words, it’s an API specification. Unlike CUDA, it is not an extension to C or C++. Instead, it is a pure C++ embedded Domain-Specific Language (DSL) that works based on templates and headers. It has amazing abstractions including unified shared memory, command queues, lambdas as kernels and lot more. A great book to learn more about SYCL is available for free.
SYCL and some implementations

Since SYCL is an API spec/standard, there are multiple projects implementing SYCL. Some notable ones include DPC++, AdaptiveCpp and ComputeCPP. DPC++ is Intel’s SYCL implementation that works for most of their devices along with Nvidia/AMD cards. I have earlier used it and benchmarked BLAS across different GPUs. It actually works and performs quite well. This convinced me that a portable CUDA implementation is indeed possible. While well-documented, I was not too fond of the behemoth codebase – after all, it’s a fork of the LLVM monorepo.
AdaptiveCpp
Enter AdaptiveCpp! Formerly it was called hipSYCL because it started as an implementation targeting AMD GPUs in addition to Nvidia GPUs. However, it is not actually a product of AMD and is actually a project by Aksel Alpay from University of Heidelberg. The fact that it’s a project by a single person meant the architecture had to be robust and the codebase manageable. This contrasts with Intel’s implementation, where they can afford to allocate more personnel to the project. AdaptiveCpp caught my eye when the latest release started to outperform Intel’s DPC++.
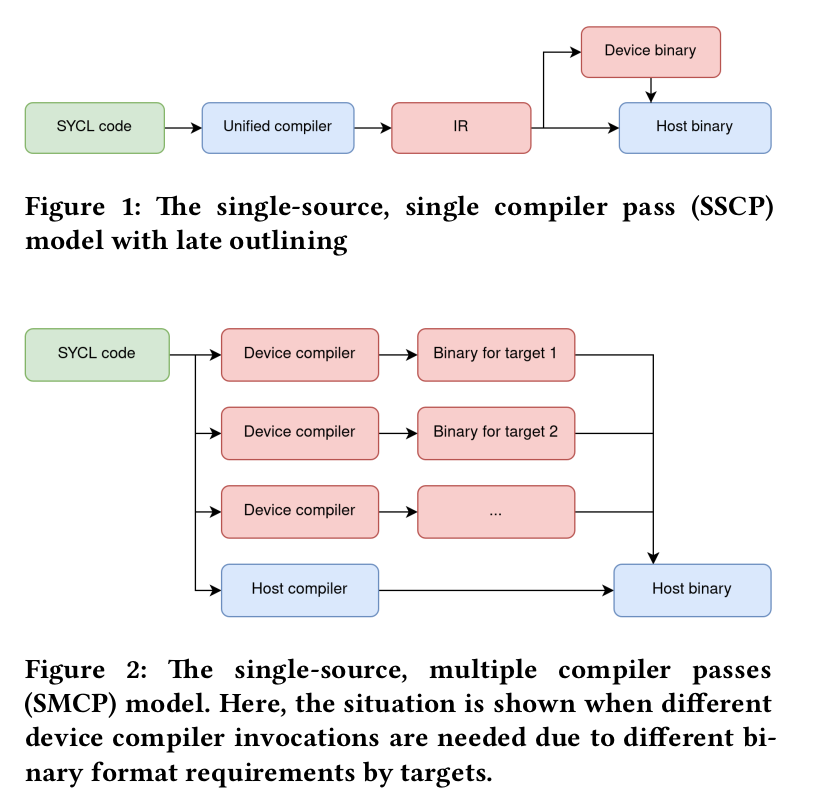
I was really sold on AdaptiveCpp (acpp henceforth) when I read that it can now do single source, single pass compilation! The importance of this is hard to understate if you understand how other SYCL compilers operate. While SYCL standard requires you to have single source to be shared for host and device, compilers can implement multiple passes on the same source. For example, DPC++ compiles same SYCL file twice: once for the CPU and once for the GPU. DPC++ later links the host binary with device binary and creates a fat binary.
AdaptiveCpp abstracted out this requirement and created two stages of compilation – one for ahead of time (AOT) and another for run time (RT). AOT stage parses the SYCL source file in one single go and creates an intermediate representation to be passed to RT stage. This representation is independent of devices and is translated to actual device code during runtime at RT stage. This design not only significantly speeds up compilations but is also aesthetically pleasing. In other words, acpp can do just-in-time or JIT compilation. See the below figure for comparison between acpp (figure 1, SSCP) and DPC++ (figure 2, SMCP):
Comparison between single source single compiler pass and single source multiple compiler pass. Source
Building AdaptiveCpp
As usual, let’s distrobox to create a new environment and install acpp and its dependencies inside. We’ll try to keep the dependencies minimal to understand what’s really required.
distrobox create --name acpp-reactor --image ubuntu:22.04
distrobox enter acpp-reactor
Let’s begin by installing LLVM. We’ll follow instructions from here.
sudo apt update && sudo apt install -y lsb-release wget software-properties-common gnupg
wget https://apt.llvm.org/llvm.sh #Convenience script that sets up the repositories
chmod +x llvm.sh
sudo ./llvm.sh 16 #Set up repositories for clang 16
sudo apt update && sudo apt install -y libclang-16-dev clang-tools-16 libomp-16-dev llvm-16-dev lld-16
Next, let’s install acpp’s other dependencies:
sudo apt install -y python3 cmake libboost-all-dev git build-essential
Now, it’s time to install drivers for our GPU. For this build, I’m using an Intel Arc 770. For other devices, follow the instructions from my earlier post:
# Drivers for Intel GPUs
wget -qO - https://repositories.intel.com/gpu/intel-graphics.key | \
sudo gpg --dearmor --output /usr/share/keyrings/intel-graphics.gpg
echo "deb [arch=amd64,i386 signed-by=/usr/share/keyrings/intel-graphics.gpg] https://repositories.intel.com/gpu/ubuntu jammy client" | \
sudo tee /etc/apt/sources.list.d/intel-gpu-jammy.list
sudo apt update
sudo apt install -y \
intel-opencl-icd intel-level-zero-gpu level-zero \
intel-media-va-driver-non-free libmfx1 libmfxgen1 libvpl2 \
libegl-mesa0 libegl1-mesa libegl1-mesa-dev libgbm1 libgl1-mesa-dev libgl1-mesa-dri \
libglapi-mesa libgles2-mesa-dev libglx-mesa0 libigdgmm12 libxatracker2 mesa-va-drivers \
mesa-vdpau-drivers mesa-vulkan-drivers va-driver-all vainfo hwinfo clinfo xpu-smi
sudo apt install -y \
libigc-dev intel-igc-cm libigdfcl-dev libigfxcmrt-dev level-zero-dev
Now, clone acpp and build it:
git clone https://github.com/AdaptiveCpp/AdaptiveCpp
cd AdaptiveCpp
mkdir build && cd build
cmake -DWITH_LEVEL_ZERO_BACKEND=ON ..
make -j
sudo make install
Check the available devices using:
$ acpp-info -l
=================Backend information===================
Loaded backend 0: OpenMP
Found device: hipSYCL OpenMP host device
Loaded backend 1: Level Zero
Found device: Intel(R) Arc(TM) A770 Graphics
Data Parallel C++
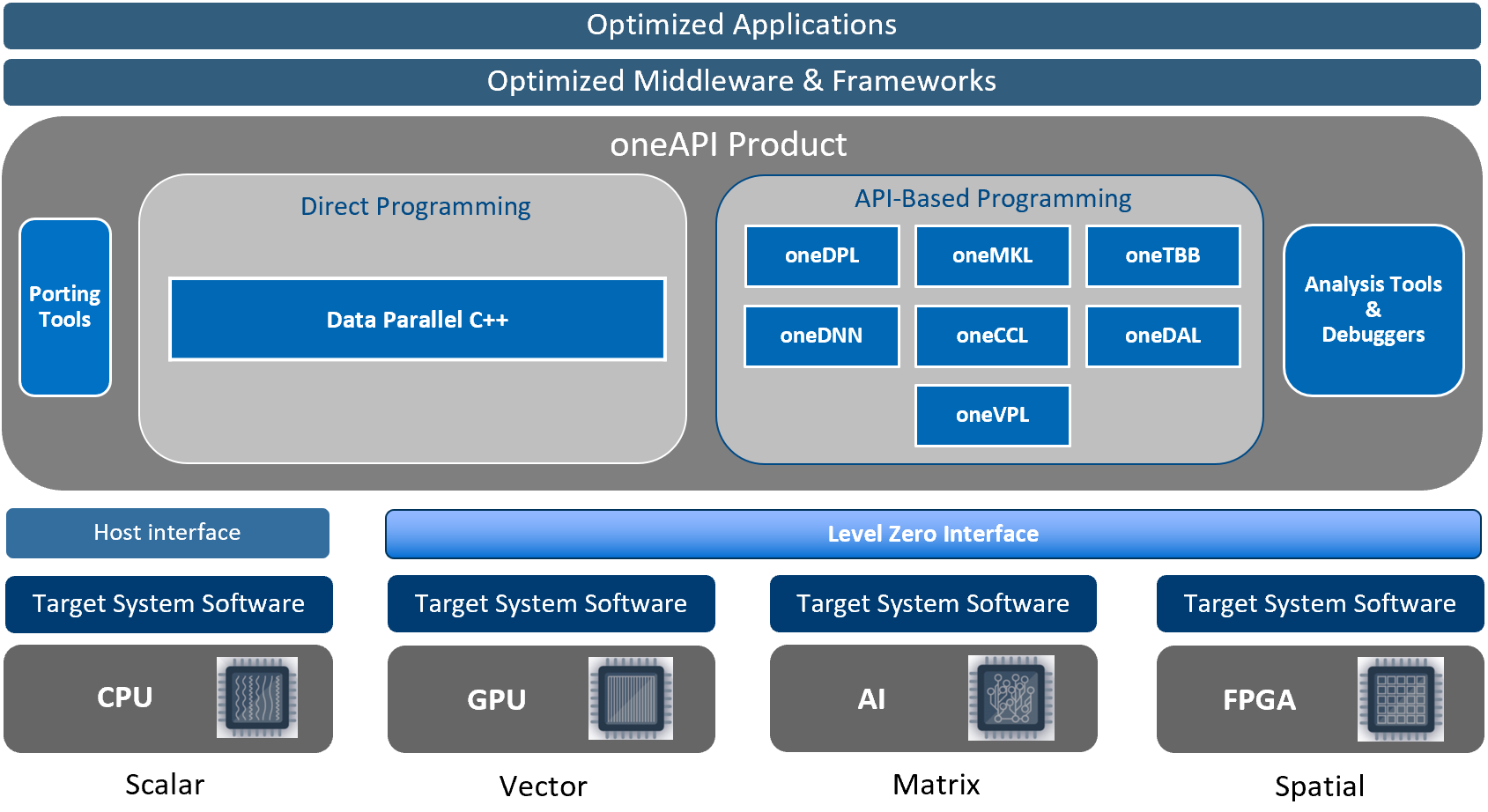
As I previously explained, DPC++ or Data Parallel C++ is Intel’s SYCL implementation. Although Intel compilers have a long history, Intel recently acquired a company called CodePlay to further develop SYCL. Despite being funded by Intel, the implementation works amazingly well across all GPUs. For most people, this should be the go-to SYCL distribution because the ecosystem is quite advanced by now. Many libraries interoperate with the DPC++ implementation, including OneMKL for linear algebra routines and OneDNN for neural network routines.
The DPC++ implementation resides inside a fork of the LLVM monorepo. Unfortunately, this means there’s a lot of code to review to understand what’s happening inside the repo. Monorepos are excellent for tight integration but can be intimidating for newcomers. While the codebase might not be as elegantly designed as AdaptiveCpp’s, it is certainly feature-rich, with immense development throughput. The group also produces some very interesting research. One paper that caught my eye was implementation of SYCL that uses MLIR – another project from LLVM group. Unfortunately, I couldn’t figure out how to hack on it, and my issue has been unanswered for about two weeks now.
How DPC++ fits in. Source
Building DPC++
This is the distribution of SYCL I recommend for most people. There are easy ways to install this without building from source by using Intel’s binary repositories. I have written about that in an earlier post. But let’s build from source because it’s fun :).
Let’s create a distrobox as before:
distrobox create --name dpcpp-reactor --image ubuntu:22.04
distrobox enter dpcpp-reactor
and Install GPU drivers:
# Drivers for Intel GPUs
wget -qO - https://repositories.intel.com/gpu/intel-graphics.key | \
sudo gpg --dearmor --output /usr/share/keyrings/intel-graphics.gpg
echo "deb [arch=amd64,i386 signed-by=/usr/share/keyrings/intel-graphics.gpg] https://repositories.intel.com/gpu/ubuntu jammy client" | \
sudo tee /etc/apt/sources.list.d/intel-gpu-jammy.list
sudo apt update
sudo apt install -y \
intel-opencl-icd intel-level-zero-gpu level-zero \
intel-media-va-driver-non-free libmfx1 libmfxgen1 libvpl2 \
libegl-mesa0 libegl1-mesa libegl1-mesa-dev libgbm1 libgl1-mesa-dev libgl1-mesa-dri \
libglapi-mesa libgles2-mesa-dev libglx-mesa0 libigdgmm12 libxatracker2 mesa-va-drivers \
mesa-vdpau-drivers mesa-vulkan-drivers va-driver-all vainfo hwinfo clinfo xpu-smi
sudo apt install -y \
libigc-dev intel-igc-cm libigdfcl-dev libigfxcmrt-dev level-zero-dev
Install the dependencies of DPC++:
sudo apt update
sudo apt install -y build-essential git cmake ninja-build python3 pkg-config
Let’s create a workspace and clone the repo into it:
mkdir sycl_workspace
cd sycl_workspace
export DPCPP_HOME=`pwd`
git clone https://github.com/intel/llvm -b sycl
Now compile using the following command. Since DPC++ is structured as a fork of the LLVM monorepo, this means the entire LLVM will be built along with DPC++. Because DPC++ is structured as a fork of LLVM monorepo, this means that whole LLVM will be built along with DPC++. So grab a coffee or something – this is gonna take some time.
python $DPCPP_HOME/llvm/buildbot/configure.py
python $DPCPP_HOME/llvm/buildbot/compile.py
Once done, execute the following to install it in your $PATH. I recommend adding it to ~/.bashrc if you want this to be permanent:
export PATH=$DPCPP_HOME/llvm/build/bin:$PATH
export LD_LIBRARY_PATH=$DPCPP_HOME/llvm/build/lib:$LD_LIBRARY_PATH
Check the available devices using:
$ sycl-ls
[opencl:gpu][opencl:0] Intel(R) OpenCL Graphics, Intel(R) Arc(TM) A370M Graphics OpenCL 3.0 NEO [23.35.27191.42]
[opencl:gpu][opencl:1] Intel(R) OpenCL Graphics, Intel(R) Iris(R) Xe Graphics OpenCL 3.0 NEO [23.35.27191.42]
Unfortunately, I couldn’t figure out how to get the runtimes working by building from source. However, the support for various GPUs is well-tested, and my benchmarks demonstrate that their performance is quite good. If you have an AMD GPU, it would appear something like this:
$ sycl-ls
[opencl:acc:0] Intel(R) FPGA Emulation Platform for OpenCL(TM), Intel(R) FPGA Emulation Device OpenCL 1.2 [2023.16.12.0.12_195853.xmain-hotfix]
[opencl:cpu:1] Intel(R) OpenCL, AMD Custom APU 0405 OpenCL 3.0 (Build 0) [2023.16.12.0.12_195853.xmain-hotfix]
[ext_oneapi_hip:gpu:0] AMD HIP BACKEND, gfx1030 gfx1030 [HIP 50422.80]
Conclusion
A strong alternative standard/framework to CUDA, funded by the broader industry, aims to dethrone Nvidia’s dominance in AI. The Khronos Group created the standard, and there are a few competing implementations. AdaptiveCpp offers a more elegant but somewhat incomplete implementation, while DPC++ is more feature-rich. Future efforts in this area should focus on creating portable and performant GPU kernels compatible with all GPUs.
Errata:
Thanks to the review from Aksel, here are some corrections:
- ComputeCpp is dead after Intel acquired CodePlay
- AdaptiveCpp started as personal project of Aksel. Now there are university students paid to work on it along with external contributors
- AdaptiveCpp has extensions that DPC++ doesn’t have like C++ offloading support